MOTIFSIM is a tool for detecting similarity in a single or multiple DNA motif datasets. It accepts nine different input formats from several motif finders and generates the results in multiple HTML, PDF, and Text files. The tool combines all input datasets into one list and performs pair-wise comparisons on the entire list. MOTIFSIM converts all input motifs into position specific probability matrices for comparisons. The tool reports the global significant motifs, the global and local significant motifs, as well as best matches for each motif in the combined list or in a single dataset.
Version 2.2 allows combining similar motifs in the results. It also allows comparing the global significant motifs as well as every motif in the combined list with motifs in a database. In addition, the relationship between motifs can be visualized via motif tree.
MOTIFSIM accepts the following motif input formats in text file (.txt).
| Input Format | Example | Restriction |
| TRANSFAC | NA Test1 XX DE Test1 XX P0 A C G T 01 4 36 5 5 C 02 39 0 9 2 A 03 10 30 0 10 C 04 2 1 38 9 G 05 4 3 5 38 T 06 9 0 31 10 G 07 4 6 21 10 G 08 1 9 10 30 T XX NA Test2 XX DE Test2 XX P0 A C G T 01 0 40 10 0 C 02 38 0 10 2 A 03 0 30 10 10 C 04 2 11 28 9 G 05 9 3 10 28 T XX |
One empty line must be present to separate two motifs. Space or tab can be used to separate matrix's elements. |
| TRANSFAC-like | DE Test1 01 4 31 5 5 C 02 29 0 9 2 A 03 0 30 0 10 C 04 2 1 28 9 G 05 4 3 5 28 T 06 9 0 31 0 G XX DE Test2 01 0 40 10 0 C 02 38 0 10 2 A 03 0 30 10 10 C 04 2 11 28 9 G 05 9 3 10 28 T 06 50 0 0 0 A 07 0 50 0 0 C 08 0 0 50 0 G 09 0 0 0 50 T XX |
Columns 2, 3, 4, and 5 in the matrix represent A, C, G, and T values respectively. One empty line must be present to separate two motifs. Space or tab can be used to separate matrix's elements. |
| TRANSFAC-like | DE sscCCCGCGcs 1 5 15 9 5 2 4 18 10 2 3 0 23 8 3 4 1 29 4 0 5 0 28 6 0 6 0 27 7 0 7 0 0 34 0 8 0 34 0 0 9 0 2 32 0 10 4 16 8 6 11 0 11 18 5 XX DE atactttggc 1 1 0 0 0 2 0 0 0 1 3 1 0 0 0 4 0 1 0 0 5 0 0 0 1 6 0 0 0 1 7 0 0 0 1 8 0 0 1 0 9 0 0 1 0 10 0 1 0 0 XX |
Columns 2, 3, 4, and 5 in the matrix represent A, C, G, and T values respectively. One empty line must be present to separate two motifs. Space or tab can be used to separate matrix's elements. |
| PSSM | >TFW3 73 81 407 61 44 578 0 0 485 65 0 72 0 570 52 0 79 0 0 543 0 0 622 0 >TFW1 0 0 1 39 0 0 0 40 4 1 33 2 6 25 2 7 7 2 25 6 2 33 1 4 40 0 0 0 39 1 0 0 |
Columns 1, 2, 3, and 4 in the matrix represent A, C, G, and T values respectively. One empty line must be present to separate two motifs. Space or tab can be used to separate matrix's elements. |
| Jaspar | >NR4A2 A [ 8 13 0 3 2 0 14 3 ] C [ 1 0 0 0 2 13 0 8 ] G [ 3 1 13 11 0 0 0 2 ] T [ 2 0 1 0 10 1 0 1 ] >RORA_1 A [15 9 6 11 21 0 0 0 0 25 ] C [ 1 1 12 2 0 0 0 0 25 0 ] G [ 2 0 4 5 4 25 25 0 0 0 ] T [ 7 15 3 7 0 0 0 25 0 0 ] |
One empty line must be present to separate two motifs. Space or tab can be used to separate matrix's elements. |
| MEME's output | -------------------------------------------------------------------------------- Motif 1 position-specific probability matrix -------------------------------------------------------------------------------- letter-probability matrix: alength= 4 w= 11 nsites= 142 E= 6.0e-015 0.000000 0.598592 0.176056 0.225352 0.000000 0.626761 0.000000 0.373239 0.000000 0.000000 0.000000 1.000000 0.000000 0.408451 0.514085 0.077465 0.091549 0.823944 0.028169 0.056338 0.133803 0.690141 0.000000 0.176056 0.042254 0.281690 0.000000 0.676056 0.007042 0.683099 0.197183 0.112676 0.197183 0.000000 0.000000 0.802817 0.000000 0.084507 0.690141 0.225352 0.091549 0.605634 0.169014 0.133803 -------------------------------------------------------------------------------- Motif 2 position-specific probability matrix -------------------------------------------------------------------------------- letter-probability matrix: alength= 4 w= 14 nsites= 24 E= 6.3e-010 0.833333 0.000000 0.166667 0.000000 0.000000 1.000000 0.000000 0.000000 0.875000 0.000000 0.000000 0.125000 0.083333 0.875000 0.041667 0.000000 0.958333 0.000000 0.000000 0.041667 0.125000 0.875000 0.000000 0.000000 0.833333 0.166667 0.000000 0.000000 0.000000 0.750000 0.000000 0.250000 0.666667 0.000000 0.208333 0.125000 0.000000 0.833333 0.041667 0.125000 0.791667 0.125000 0.083333 0.000000 0.000000 1.000000 0.000000 0.000000 0.708333 0.000000 0.083333 0.208333 0.000000 0.958333 0.000000 0.041667 |
One empty line must be present to separate two motifs. Space or tab can be used to separate matrix's elements. |
| Consensus sequence | >C001 CYCYYSHGGCCASMAGAGGGCRCYAGATCCCCT >C002 WWWWWWWWWWWWAAAAAAAAAWWAAWWWWW >C003 VTGYRYRYACACACACAYRCAYRYR >C004 SNSVCCCSBCCCCCSCCCCCSSY >C005 SCSCSSSSSCSSCSCCSSSSCCSSSSSSC >C006 TWWWAAAAAAWWAAAAWWAAAAAAAAAA >C007 MYVGAGGCCAGAAGAGGGCAYCAGATYCCHT |
Motif is in IUPAC format. One empty line must be present to separate two motifs. |
| Sequence Alignment | >Test1 GATACGTGGCAAAACCCTGGG GCCACGT-CCGGGAACCTGGG CGCATGTGCACCAATTACACC ACGACGTGTTCCCAAATTTTT CACACGTGCCCCCCAAGTTTG GGGGGTTACACCCTTTTAAAA CCAAGTTTAAGGGGTTTTGGA AAACCGGTTAAAACCTTGCGC >Test2 CCCAATAGCTTTT-TTTTTTAAACCCCC-CC GGGTGTGCGCGACCACCAAAATTTTAAAAAA AAACCCTTTGGGCCCGGGTTAAACCCCGGGG TTTTTTCCCAAACCCAAAGGGTTTTTCGCCC CACAAAAACCGGTTTTTTGCCGCGCCCCAAA CCAAAAAACCCTT-TTTTCCCAAAAGGGGGG CACAAACACCCCCCCCCAAAATTT-TGGGCG |
One empty line must be present to separate two motifs. |
| Matrix (Horizontal) | 7 10 6 13 4 21 0 22 1 4 3 4 10 0 2 1 4 2 6 4 2 2 0 0 11 7 8 2 7 0 21 0 27 0 1 27 27 20 0 0 9 0 0 0 0 0 0 0 0 1 0 27 17 0 0 6 |
Rows 1, 2, 3, and 4 represent A, C, G, and T values respectively. One empty line must be present to separate two motifs. Space or tab can be used to separate matrix's elements. |
| Matrix (Vertical) | 0.450000 0.250000 0.000000 0.300000 0.800000 0.000000 0.000000 0.200000 0.850000 0.000000 0.150000 0.000000 1.000000 0.000000 0.000000 0.000000 0.750000 0.000000 0.250000 0.000000 0.400000 0.300000 0.050000 0.250000 0.850000 0.100000 0.000000 0.050000 0.850000 0.150000 0.000000 0.000000 1.000000 0.000000 0.000000 0.000000 0.500000 0.100000 0.400000 0.000000 0.000000 0.812500 0.125000 0.062500 0.375000 0.000000 0.000000 0.625000 0.062500 0.000000 0.937500 0.000000 0.562500 0.125000 0.187500 0.125000 0.000000 0.000000 1.000000 0.000000 0.062500 0.937500 0.000000 0.000000 |
Columns 1, 2, 3, and 4 represent A, C, G, and T values respectively. One empty line must be present to separate two motifs. Space or tab can be used to separate matrix's elements. |
Upload/Use existing files/Insert files on browser
Users can upload files, use existing files, or insert files on the browser using specified formats above to run the tool. Registered users can store uploaded files and results for an extended period. Public files including uploaded datasets and results are cleared periodically.
This version supports a maximum of twenty files.
Input file format
Specifying input file format is not required. However, input format must be one of the formats listed in the table above. Input file can also contain a mixture of nine acceptable formats above.
Number of top significant motifs
This value is currently limited to ≤ 50. This is a cutoff for the number of top global significant motifs as well as the number of top global and local significant motifs generated in the results.
This value is extended from 20 in the previous version to ≤ 50 in this version. The number of best matches is the number of motifs that are most similar to motif i (i from 1 to m) in a combined motif list M. This value is used for selecting the number of most similar motifs to motif i and report them in the results. These best matched motifs are listed in order of similarity with the most similar one on the top of the list.
Currently, the cutoff values are ≥ 50 %, ≥ 60 %, ≥ 70 %, ≥ 75 %, ≥ 80 %, ≥ 85 %, and ≥ 90 %. A value ≥ 75 % indicates a match of 75 % or greater between two motifs. We suggest to use a cutoff ≥ 75 % as this value showed a good threshold in our case studies. If a higher cutoff value is used, fewer similar motifs are generated in the results. However, these motifs are much more similar to the motif being compared.
Users can select a motif database for matching with the global significant motifs, the global and local significant motifs, as well as every motif in the combined list. Currently, the tool supports Jaspar 2016 [1], Transfac [2] (free version), and UniPROBE [3] databases.
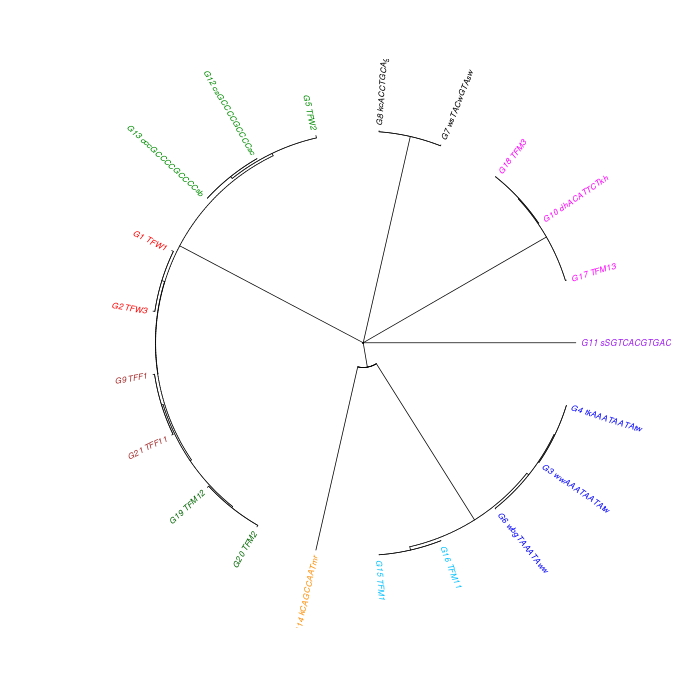
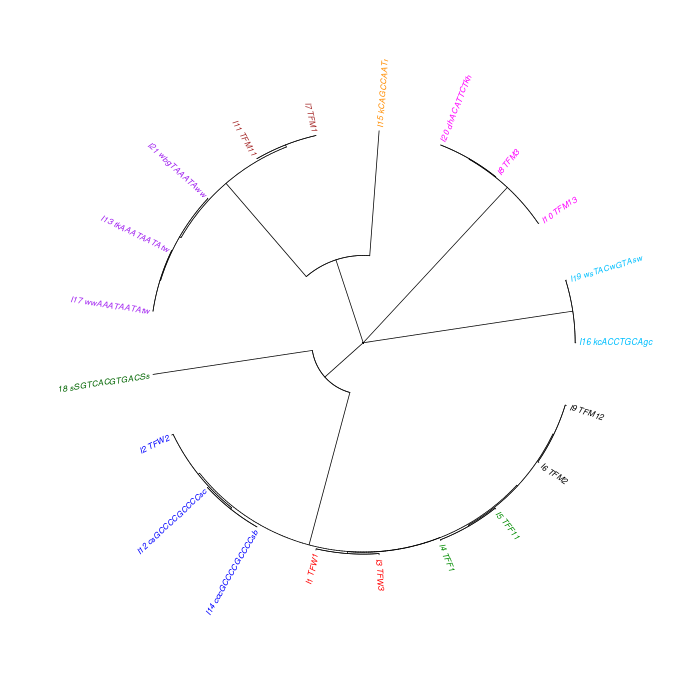
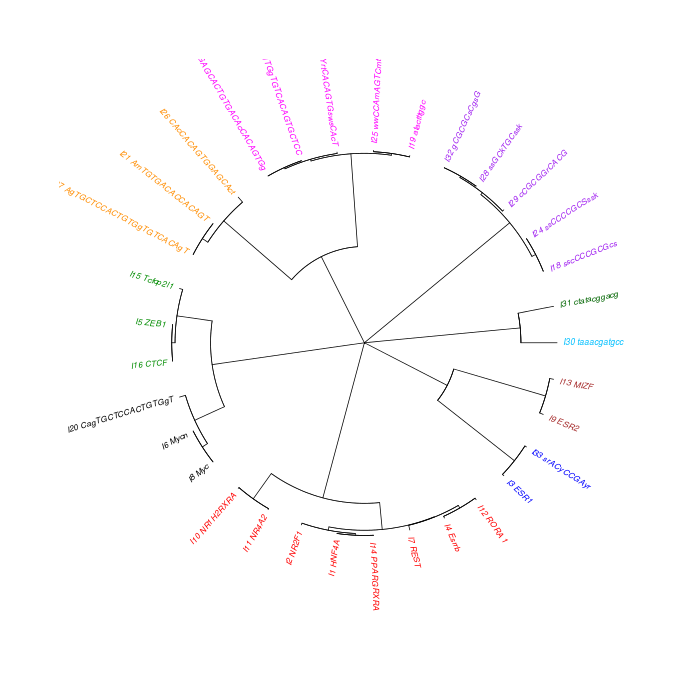
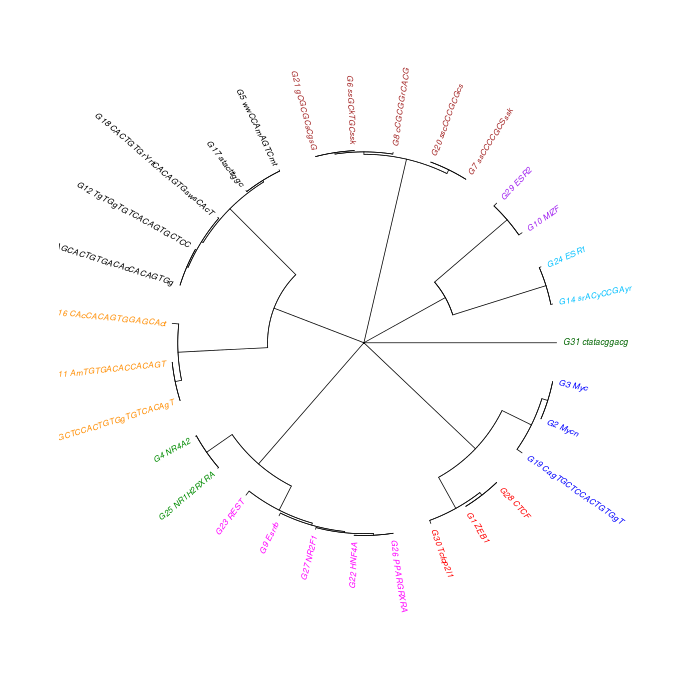
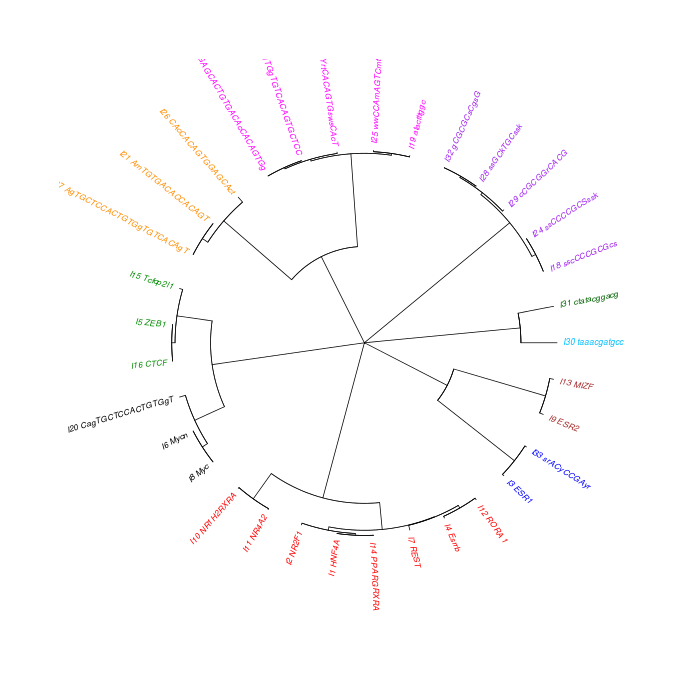
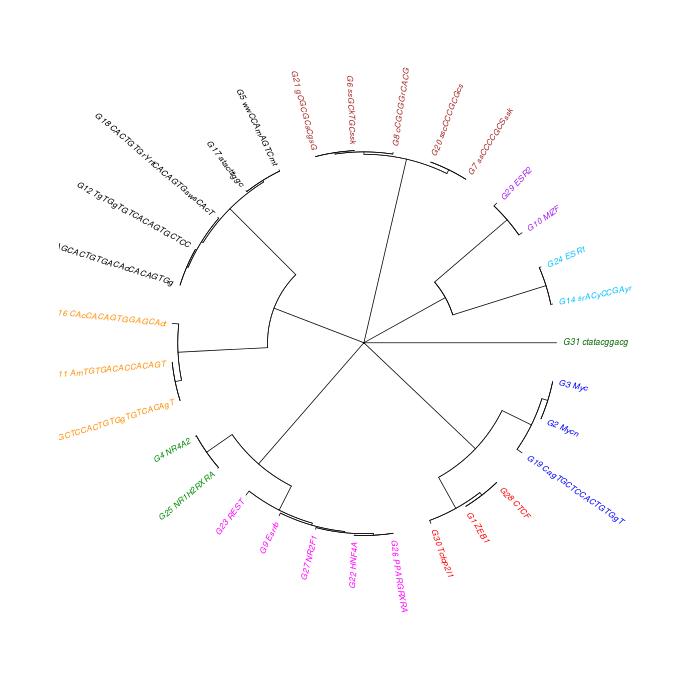
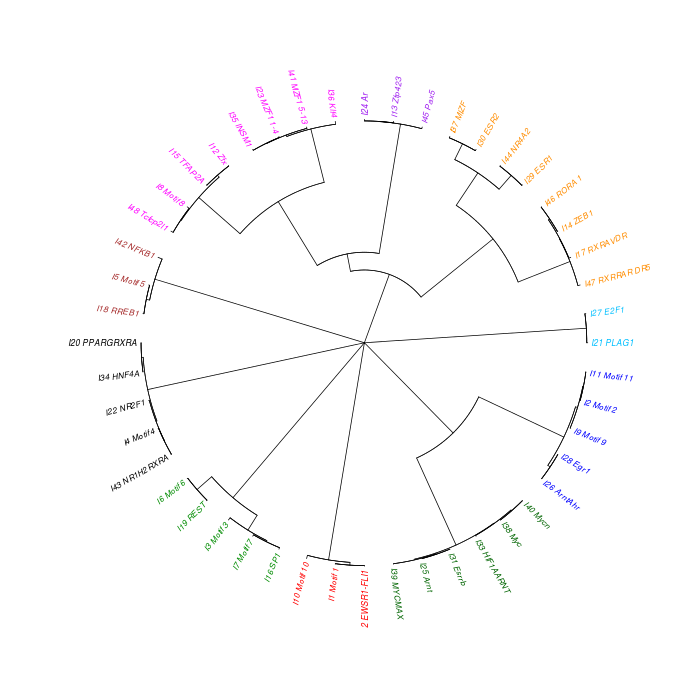
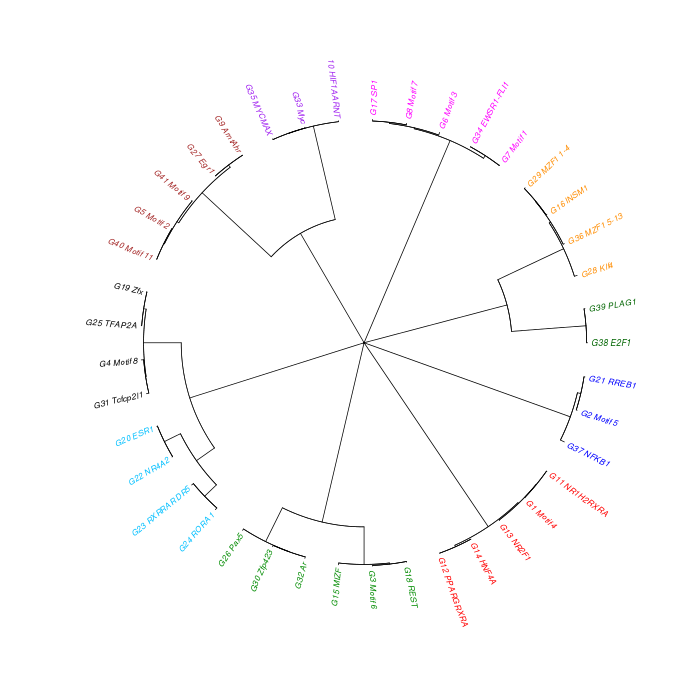
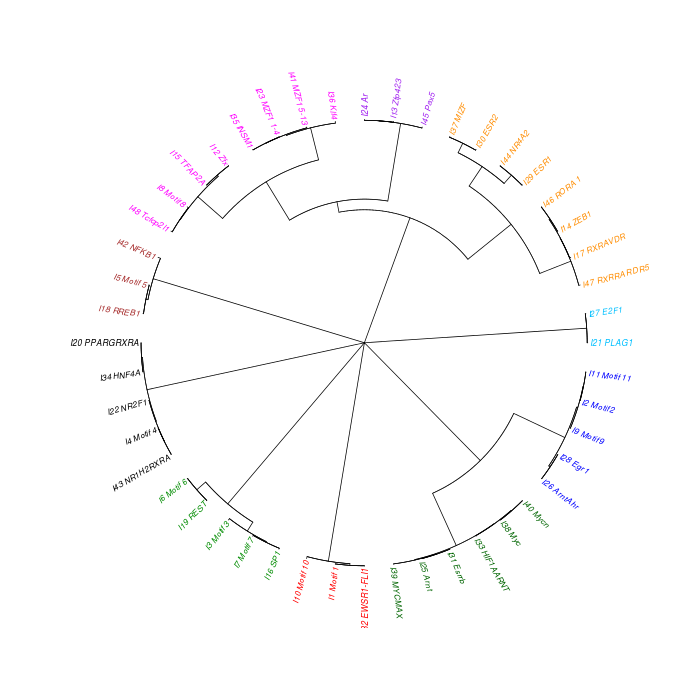
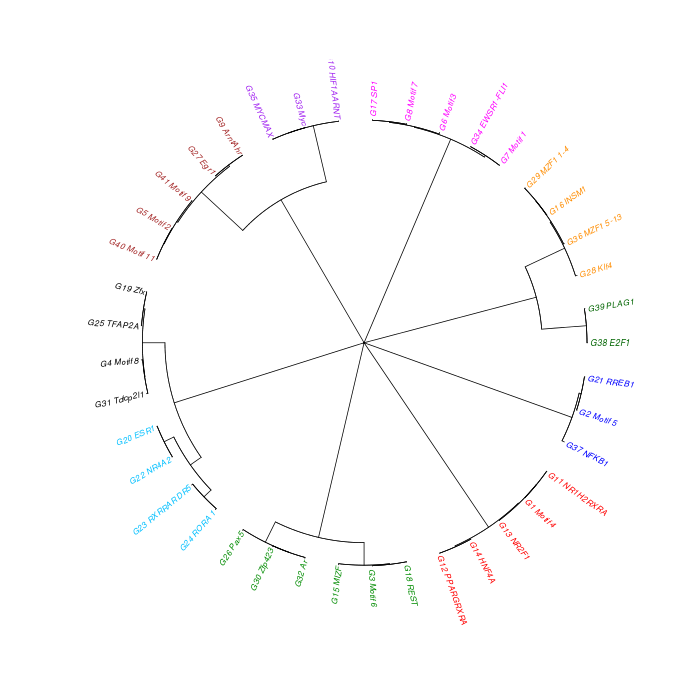
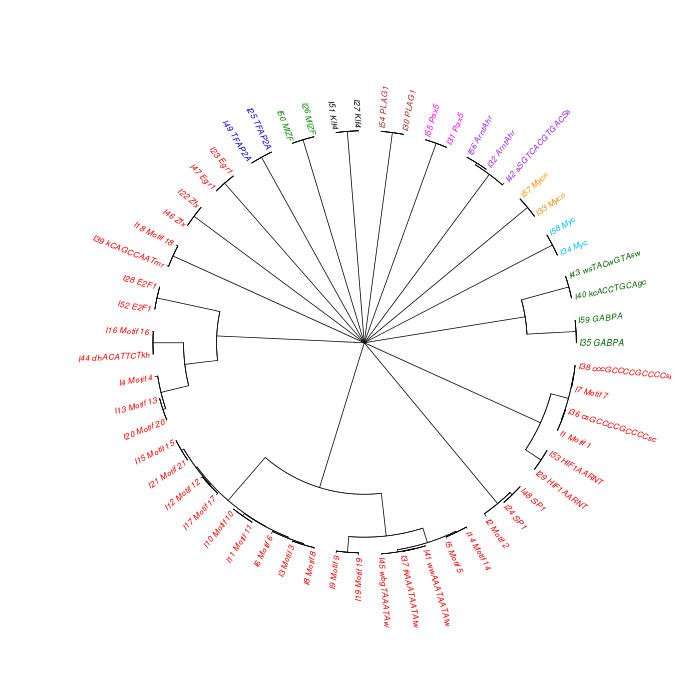
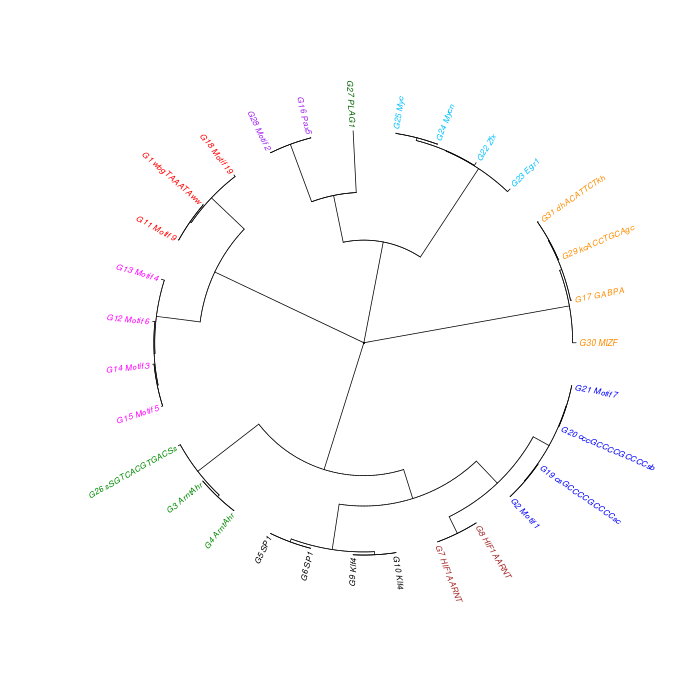
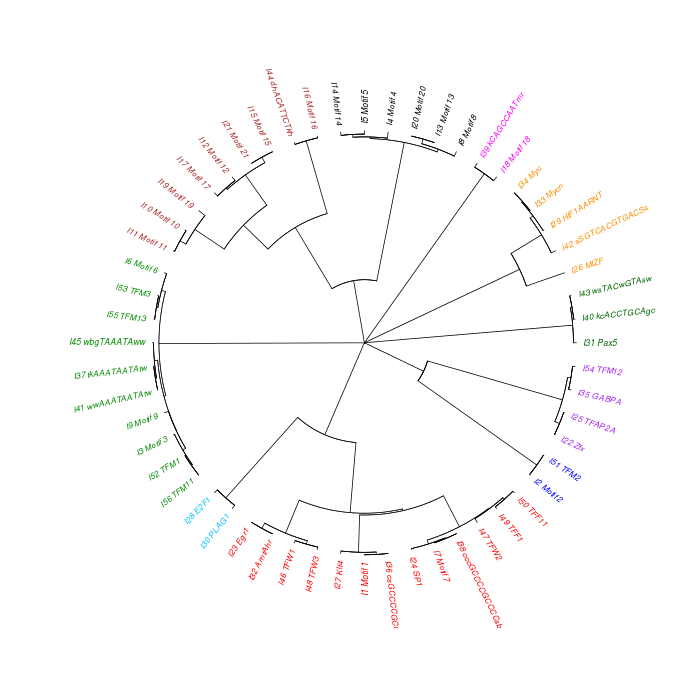
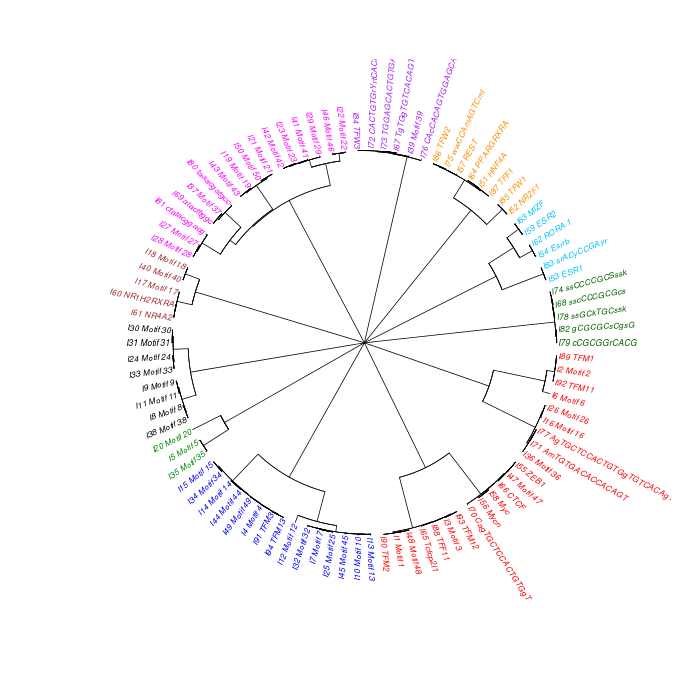
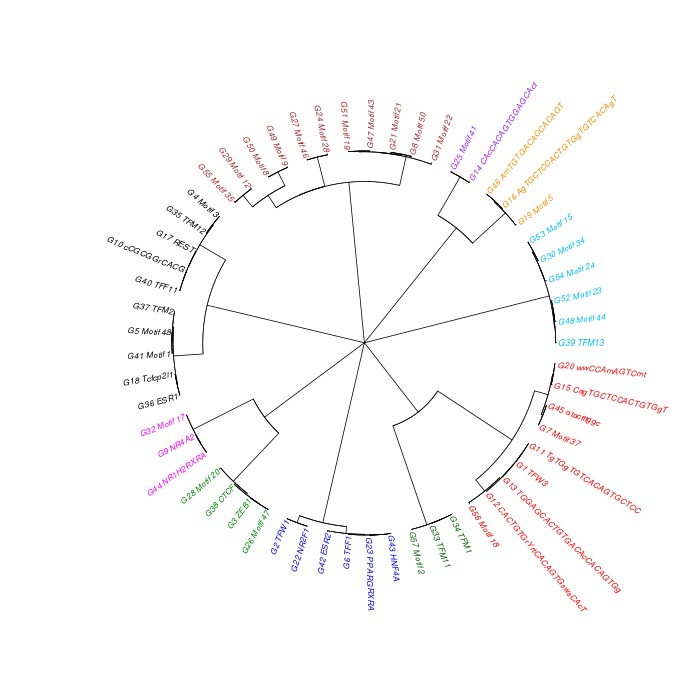
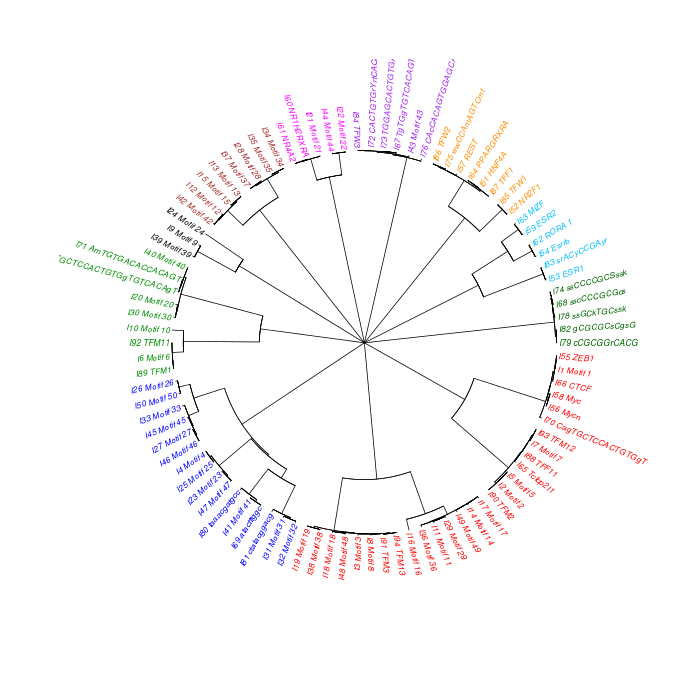
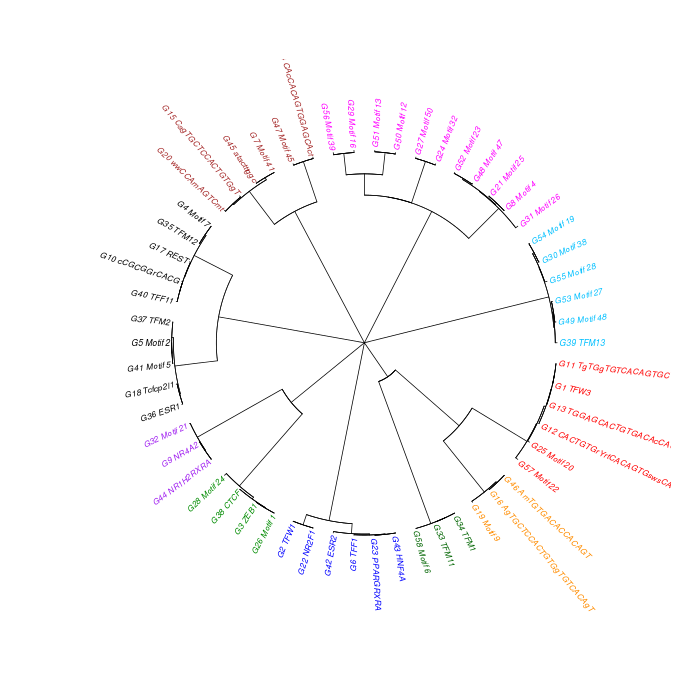
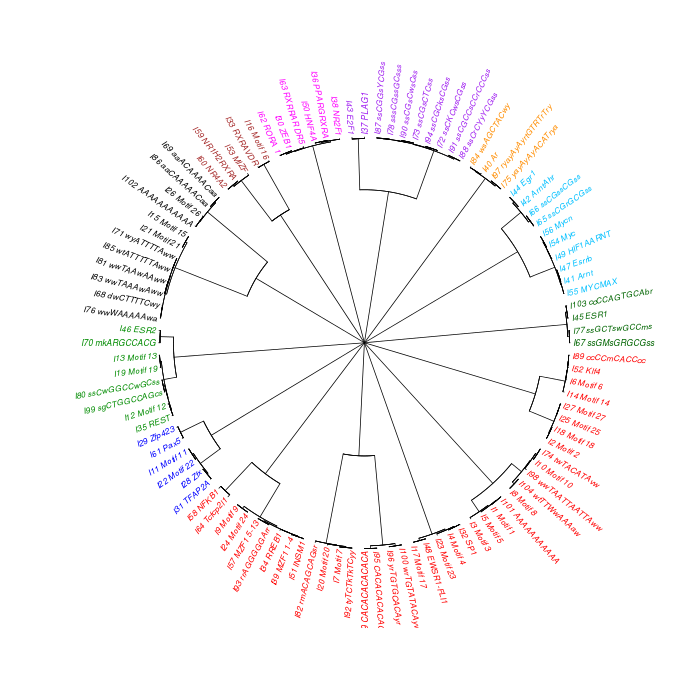
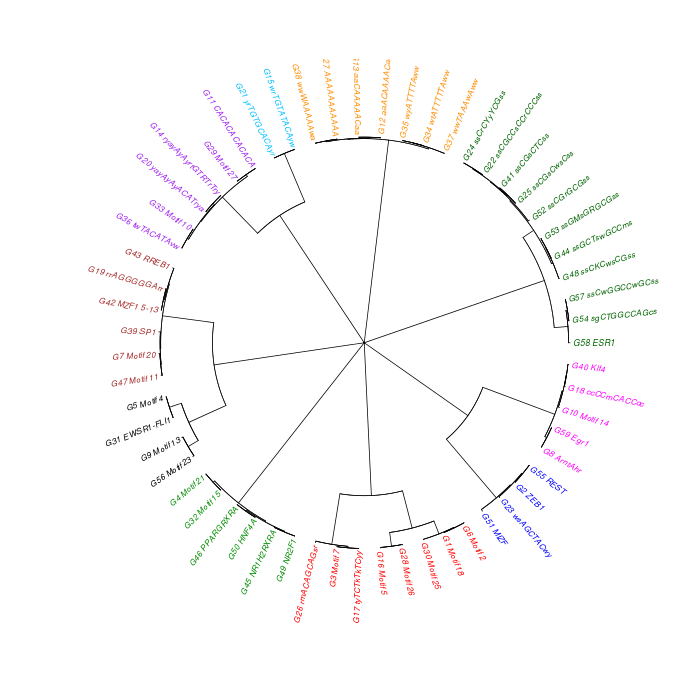
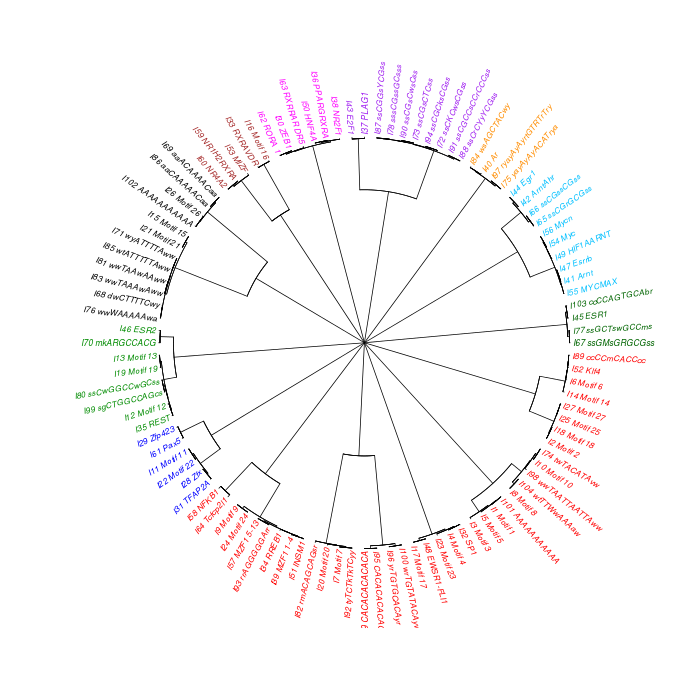
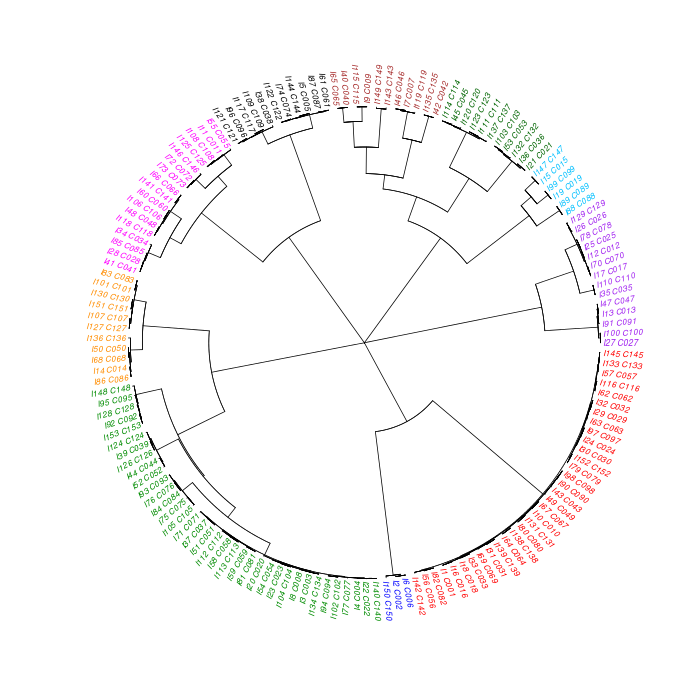
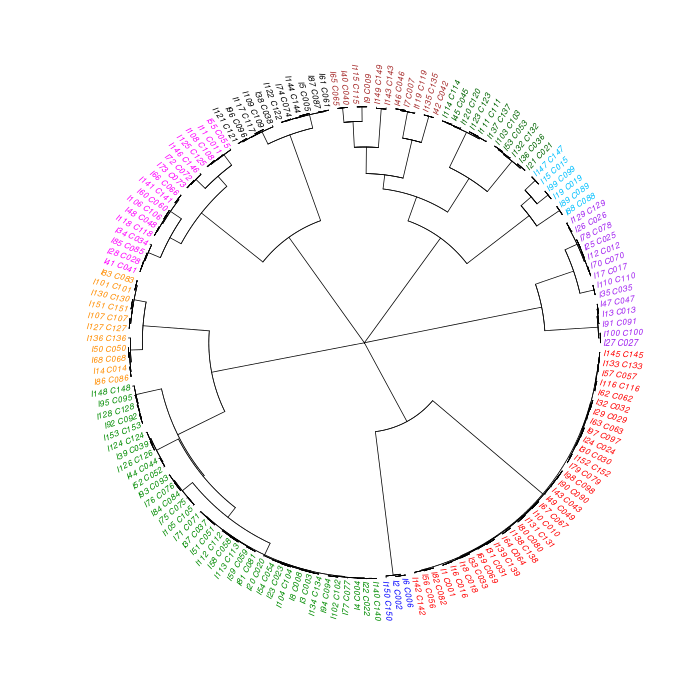
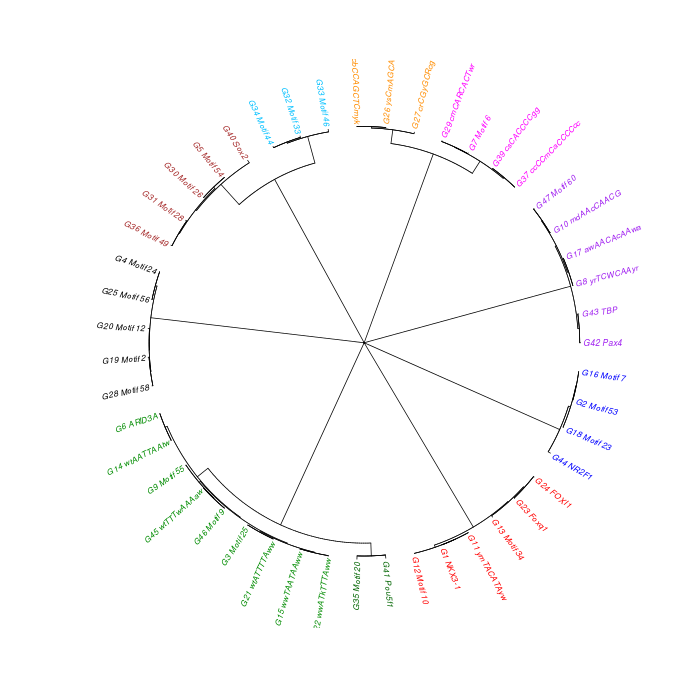
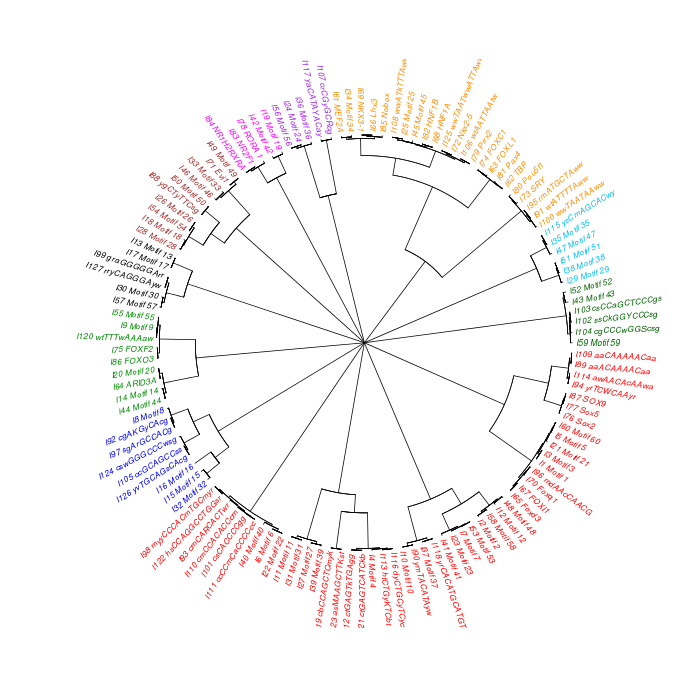
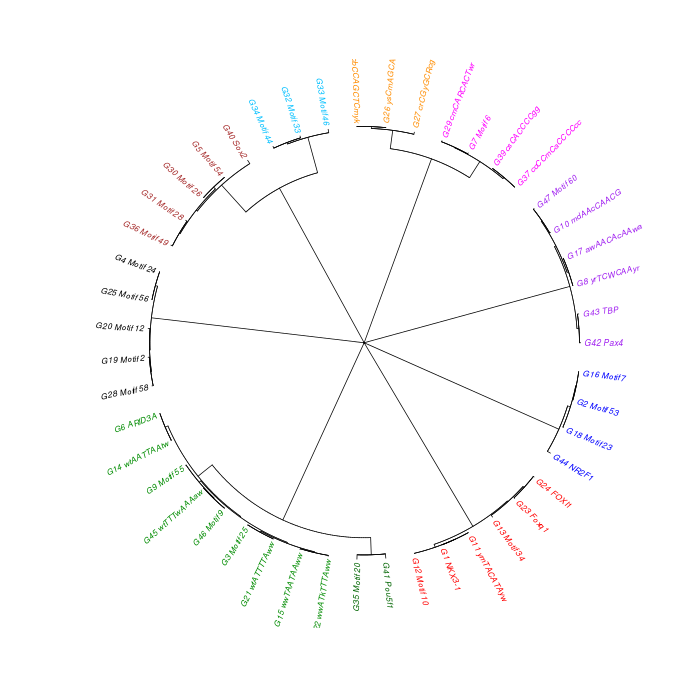
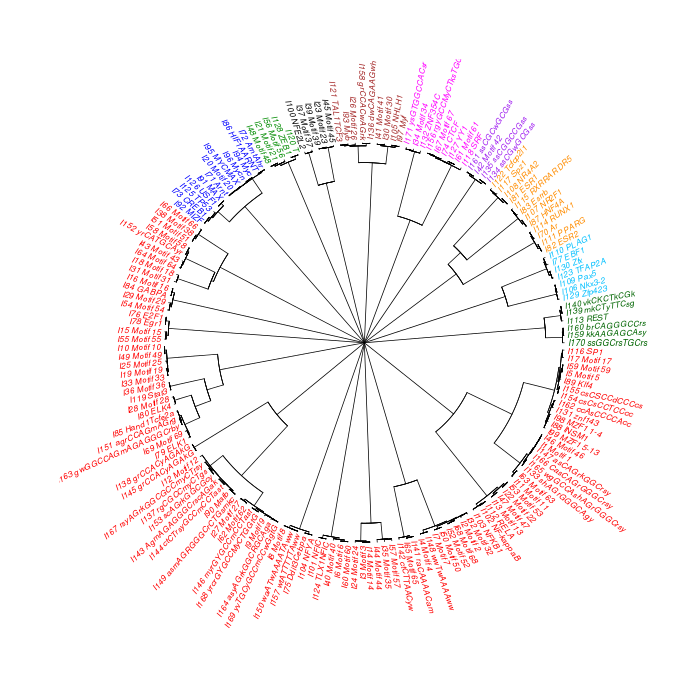
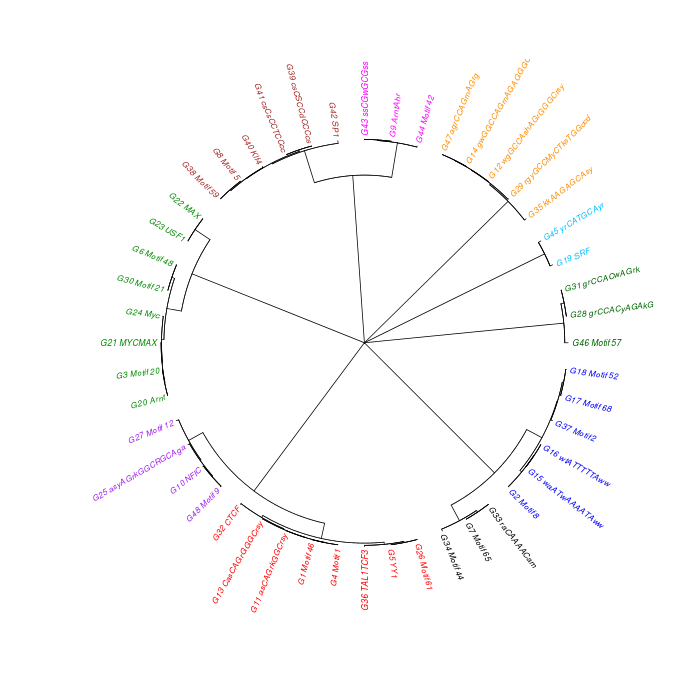
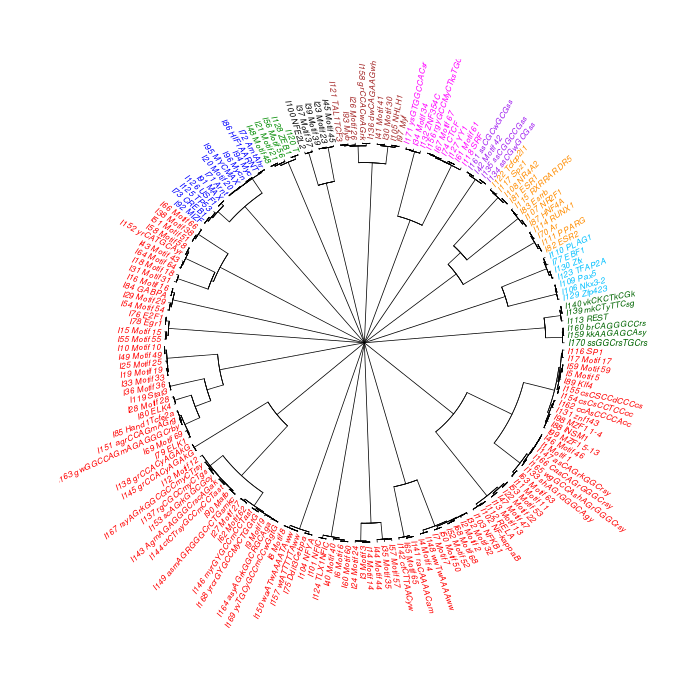
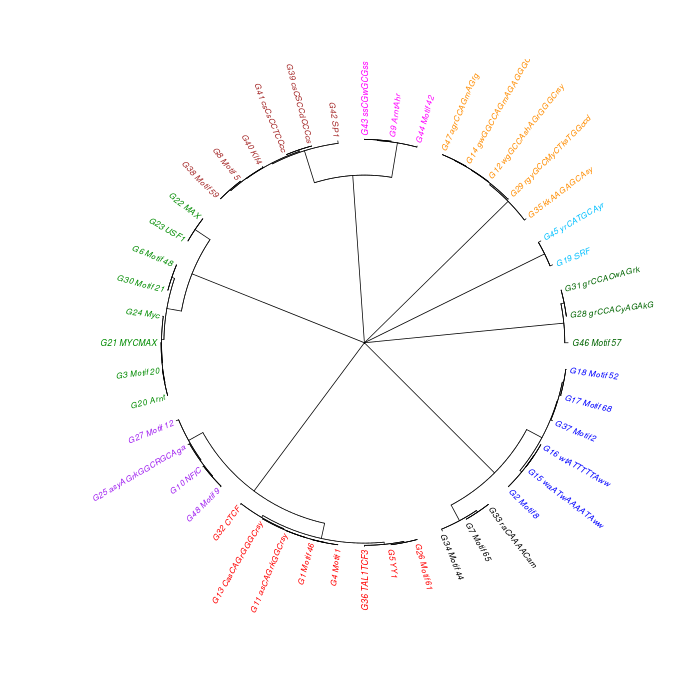
The motif tree can be generated for the global significant motifs and for the entire combined motif list as well. The tree is built using hclust function in R [4]. This function implements the hierarchical clustering algorithm. The tool generates the distance matrix for building the tree. This matrix contains best similarity scores between motifs.
Similar motifs discovered in the results can be combined into new motifs. Two similar motifs can be combined into a new motif if the new motif satisfies the similarity threshold with both of its parents.
Users can choose between (1) Global Significant Motifs Only and (2) All. The first option generates only the global significant motifs in the results. The second option generates everything and it requires longer time for processing large datasets.
The tool provides four options for output file format: Text, HTML, PDF, and All which returns all formats. HTML, PDF, and All require longer time for processing large datasets.
Users can run tests on sample data. This button selects 5 existing sample datasets and it fills in the required input parameters on the next page. Users then only need to click on the Submit button to run the test. The result page is shown after the submitted job is completed.
Unregistered users can keep the results private and retrieve them later via the search Job ID page.
The results can be viewed or downloaded in HTML, PDF, Text, and all three formats by using the links in the Results section or from View/Download Results page. The tool generates multiple results described in the table below.
| Output file name (without Job ID prefix) | Description | |
| 1. | input_motifs.txt | This file contains motifs from all datasets. The motifs are in position specific probability matrices. They are in the order of the datasets are entered by the user. |
| 2. | HTML_Results.html | The results in HTML format. Motif's logos are included. |
| 3. | HTML_Results.pdf | The results in PDF format. Motif's logos are included. |
| 4. | Results.txt | The results in Text format. Motifs are in position specific probability matrices. |
| 5. | Results_Without_Motif_Details.txt | The results in Text format. Motif's detail is not included. |
| 6. | HTML_Results_Database_Matching.html | The results match with motif database in HTML format. Motif's logos are included. |
| 7. | HTML_Results_Database_Matching.pdf | The results match with motif database in PDF format. Motif's logos are included. |
| 8. | Results_Database_Matching.txt | The results match with motif database in Text format. Motifs are in position specific probability matrices. |
| 9. | Results_Database_Matching_Without_Motif_Details.txt | The results match with motif database in Text format. Motif's detail is not included. |
| 10. | HTML_Global_Matching_Results.html | This file contains only the global significant motifs in HTML format. |
| 11. | HTML_Global_Matching_Results.pdf | Same as in (10) but the file is in PDF format. |
| 12. | Results_Global_Matching.txt | Same as in (10) but the file is in Text format. |
| 13. | HTML_Results_Database_Matching_Global_Matching.html | This file contains only the global significant motifs that match with motif database. The results are in HTML format. Motif's logos are included. |
| 14. | HTML_Results_Database_Matching_Global_Matching.pdf | Same as in (13) but the file is in PDF format. |
| 15. | Results_Database_Matching_Global_Matching.txt | This file contains only the global significant motifs that match with motif database. The results are in Text format. Motifs are in position specific probability matrices. |
| 16. | Results_Combined_Motifs_Global_Matching.txt | This file contains combined motifs for the global significant motifs and their best matches. The motifs are combined in a pair-wise fashion. The motifs are in IUPAC format. Pair-wise matching information is included. |
| 17. | Results_Combined_Motifs_Global_and_Local_Matching.txt | This file contains combined motifs for the global and local significant motifs and their best matches. The motifs are combined in a pair-wise fashion. The motifs are in IUPAC format. Pair-wise matching information is included. |
| 18. | Results_Combined_Motifs_Best_Matches.txt | This file contains combined motifs for every motif and its best matches. The motifs are combined in a pair-wise fashion. The motifs are in IUPAC format. Pair-wise matching information is included. |
| 19. | Motif_Tree.html | The motif tree shows the relationship between motifs in the entire combined list. The file is in HTML format. |
| 20. | Global_Matching_Motif_Tree.html | The motif tree shows the relationship between motifs for the global significant motifs and their best matches. The file is in HTML format. |
| 21. | Motif_Tree.png | Same as in (19) but the file is in PNG image format. |
| 22. | Global_Matching_Motif_Tree.png | Same as in (20) but the file is in PNG image format. |
Each result file has two sections: Input and Results. The Input section lists input parameters entered by the user.
The result files (numbers 2-5 in the table) have three subsections for: (1) global significant motifs, (2) global and local
significant motifs, and (3) best matches for each motif.
The results match with motif database (numbers 6-9 in the table) show best matches in a motif database for each motif in the combined list.
The global matching result files (numbers 10-12 in the table) contain only the global significant motifs and their best matches.
The result files (numbers 13-15 in the table) contain only the global significant motifs and their best matches found in a motif database.
Other output information can be found in the table below.
| Output Information | Description |
| Dataset # | Dataset is numbered from 1, 2, 3, ..., n in the order they are entered. |
| Motif ID | Each motif in the combined list is assigned with a unique ID, which is an integer from 1, 2, 3, ... n, in the order of the dataset is entered. |
| Motif Name | Motif name in the input file if available. |
| Matching Format of First Motif | Matching format of the first motif in the comparison. The format can be the original motif or its reverse complement. |
| Matching Format of Second Motif | Matching format of the second motif in the comparison. The format can be the original motif or its reverse complement. |
| Direction | Matching can be in forward or backward direction. |
| Position # | Matching position number. Starting at position 1 on the top if it is in forward direction or at the bottom if it is in backward direction. |
| # of Overlap | The number of overlapping columns when matching two motifs. |
| Similarity Score | This score is described in our algorithm. |
| Alignment | Alignment of two motifs in IUPAC format. |
Test datasets came from original publication: N.T.L. Tran and C.-H. Huang, A survey of motif finding Web tools for detecting binding site motifs in ChIP-Seq data. Biology Direct, 9(4):1-22, 2014.
| Motif Dataset | Motif Input Format | Number of Motifs |
| DREME_DM230 | MEME's output | 1 |
| MEME_DM230 | MEME's output | 20 |
| PScanChIP_DM230 | Jaspar | 14 |
| RSAT_peak-motifs_DM230 | TRANSFAC-like | 10 |
| W-ChIPMotifs_DM230 | PSSM | 11 |
| MEME_DM05 | MEME's output | 46 |
| MEME-ChIP_DM05 | MEME's output | 4 |
| PScanChIP_DM05 | Jaspar | 16 |
| RSAT_peak-motifs_DM05 | TRANSFAC-like | 17 |
| W-ChIPMotifs_DM05 | PSSM | 11 |
| DREME_DM721 | MEME's output | 16 |
| MEME-ChIP_DM721 | MEME's output | 11 |
| PScanChIP_DM721 | Jaspar | 37 |
| RSAT_peak-motifs_DM721 | TRANSFAC-like | 40 |
| CisFinder_DM721_Cluster | PSSM | 153 |
| DREME_DM01 | MEME's output | 51 |
| MEME-CHIP_DM01 | MEME's output | 9 |
| PScanChIP_DM01 | Jaspar | 27 |
| RSAT_peak-motifs_DM01 | TRANSFAC-like | 40 |
| DREME_DM254 | MEME's output | 45 |
| MEME-CHIP_DM254 | MEME's output | 24 |
| PScanChIP_DM254 | Jaspar | 39 |
| RSAT_peak-motifs_DM254 | TRANSFAC-like | 63 |
Sample test results below can also be viewed or downloaded from View/Download Results page.
References
| 1. | Sandelin A, Alkema W, Engstrom P, Wasserman WW, Lenhard B: JASPAR: an open-access database for eukaryotic transcription factor binding profiles. Nucleic Acids Research 2004, 32:D91-D94. |
| 2. | Matys V, Fricke E, Geffers R, Gossling E, Haubrock M, Hehl R, Hornischer K, Karas D, Kel AE, Kel-Margoulis OV, Kloos DU, Land S, Lewicki-Potapov B, Michael H, Munch R, Reuter I, Rotert S, Saxel H, Scheer M, Thiele S, Wingender E: TRANSFAC®: transcriptional regulation, from patterns to profiles. Nucleic Acids Research 2003, 31(1):374-8. |
| 3. | Newburger N and Bulyk M. UniPROBE: an online database of protein binding microarray data on protein–DNA interactions. Nucleic Acids Research 2009, 37:D77-D82. |
| 4. | R Core Team (2016). R: A language and environment for statistical computing. R Foundation for Statistical Computing , Vienna, Austria. URL https://www.R-project.org/. |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}